

🐾SageMaker Real-time Endpoints types🐾
❓I’m often asked about the difference between real-time SageMaker endpoint types, so I’ve decided to explain what lies behind each of them and use-cases where they are most suitable. There are several types of real-time endpoints:
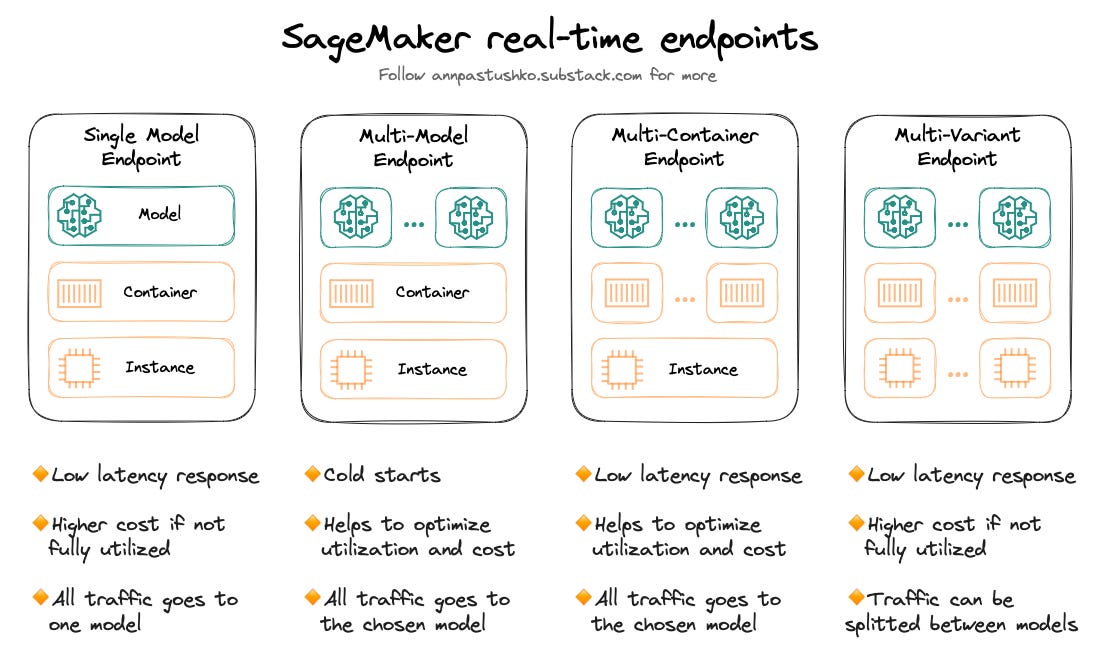
1️⃣ Single model endpoint
The simplest option, when you have one instance with a single container for specific ML framework (such as TensorFlow, Scikit-learn, etc.) and one model hosted in it.
Parameters needed to invoke: EndpointName.
Use cases: you require low latency response, your model is used consistently and endpoint utilization is high.
2️⃣ Multi-model endpoint
In this case, you have one instance with a single container for a specific ML framework, but you can host up to thousands of models in it. Models are uploaded to and offloaded from container’s memory based on incoming requests. All your models should belong to the same ML framework, as they are running in the same container to improve endpoint utilization and optimize costs.
Parameters needed to invoke: EndpointName, TargetModel.
Use cases: you are using a large number of models that are infrequently invoked and models are similar in size and response latency. Also, you tolerate some additional latency required for loading the model into the memory.
3️⃣ Multi-container endpoint
In this case, you have one instance with several containers running on it, you can host up to 15 containers on a single endpoint. It gives you ability to use different ML frameworks in one endpoint to improve endpoint utilization and optimize costs. There is no cold start while invocation because all containers are always in memory.
Parameters needed to invoke: EndpointName, TargetContainerHostname.
Use cases: you are using several models that belong to different ML frameworks and all containers exhibit similar usage patterns and have same level of resources usage. It can be useful for A/B testing or just gathering models for cost optimization.
4️⃣ Multi-variant endpoint
In this case, you have separate instances with one container running on each of them and one model hosted in each container. You create production variants for each model and specify traffic split between variants or you can invoke a specific variant directly.
Parameters needed to invoke: EndpointName, TargetVariant (optional).
Use cases: A/B testing of models.
🤓 Hope it will help to optimize your machine learning workloads and make them more cost-effective.
If you like this post, you can share APAWS newsletter with friends: