

🐾Optimisation for Glue Crawler - Incremental Crawls🐾

❓Do you use incremental crawls for your data lakes already? If no - you definitely should check it as it improves speed and reduces cost of crawls.
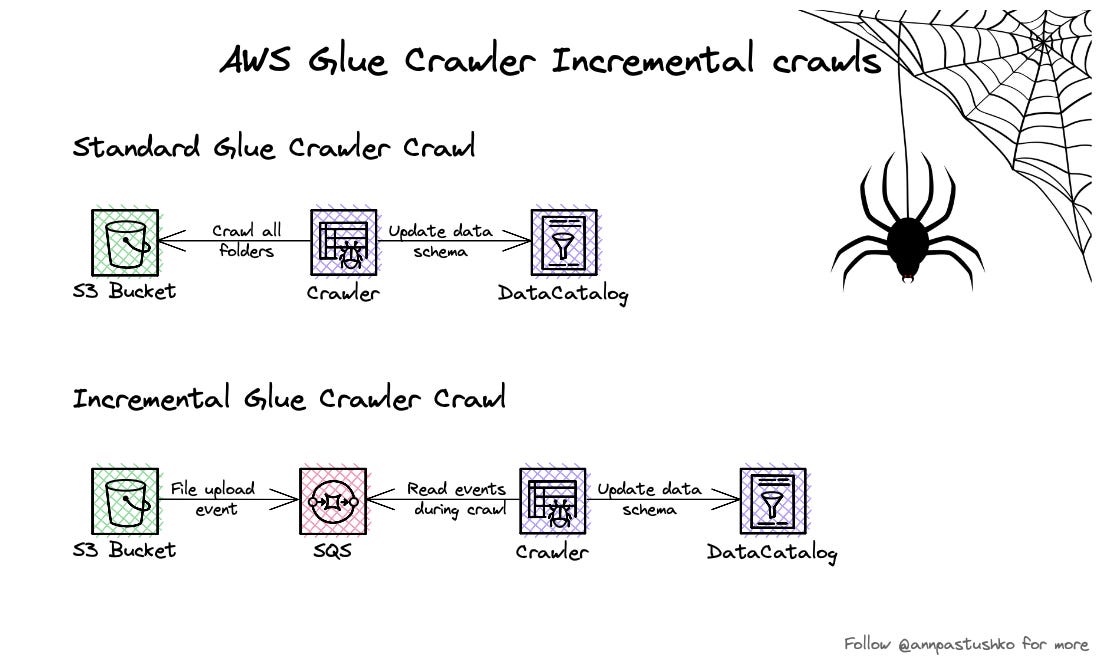
✅ Glue Incremental crawls are using S3 event notifications pulled from SQS queue to identify folders that were added and crawl only them. If queue is empty you would not pay for Crawler run.
Prerequisites for using incremental crawls:
🔹Data schema is stable across old and new files
🔹Partitions pattern are stable
Keep in mind:
🔸If Crawler discovers new files with different schema - it ignores files
🔸If Crawler discovers that files are deleted - it ignores files
🔸If Crawler discovers new partitions patterns - it can fail
If you like this post, you can share APAWS newsletter with friends: