

🐾MLOps: SageMaker vs Databricks on AWS🐾
🤓 Previously, I wrote a post about the difference between MLOps concepts in SageMaker and Databricks, but so many changes have occurred since then: release of MLflow for SageMaker Studio, the deprecation of CodeCommit and changes in MLflow approach to model approval flow. Given these significant changes, I've decided to write a new post comparing the current MLOps setups.
Databricks approach
Databricks proposes two approaches for MLOps setup described in the official documentation: deploy code and deploy model. While Databricks recommend the deploy code approach, it seems questionable to me.
In organizations where access to production data is restricted, this pattern allows the model to be trained on production data in the production environment.
Based on my experience, training models without production data access is rarely ideal — it significantly complicates the process:
Data exploration and feature engineering. Data scientists need real data for exploration, as it may have different distribution and relations between features. Model can performs worse while trained on production data, because features were created for dummy data.
Testing overhead. The requirement to validate the model with the same full set of tests three times across different environments creates unnecessary overhead.
Long development process. Even after ensuring model consistency across environments, you won't know the actual production performance until completing the entire MLOps pipeline cycle.
Increased cost. While training your model three timed, you use more computing resources which consequently increases your cost.

From my perspective, more practical scenario for using different training datasets would be when you have massive amounts of data and want to validate your hypotheses quickly on a smaller subset to avoid expensive full dataset training. In the same time, it’s applicable only for initial validation of hypothesis.
SageMaker approach
AWS recommends promoting trained model artifacts across environments rather than doing retraining in each environment, which aligns with Databricks deploy model approach and has the following advantages:
Ensures consistency of model behavior across environments, as you you use the same artifact (traceability and lineage)
Reduces compute costs, because model is trained only once
Speeds up deployment process, as you don’t need to repeat the same tests for each environment
With release of MLflow support in SageMaker, there are two options that can be used for MLOps setup:
MLflow Tracking and Model Registry
SageMaker Experiments tracking and Model Registry
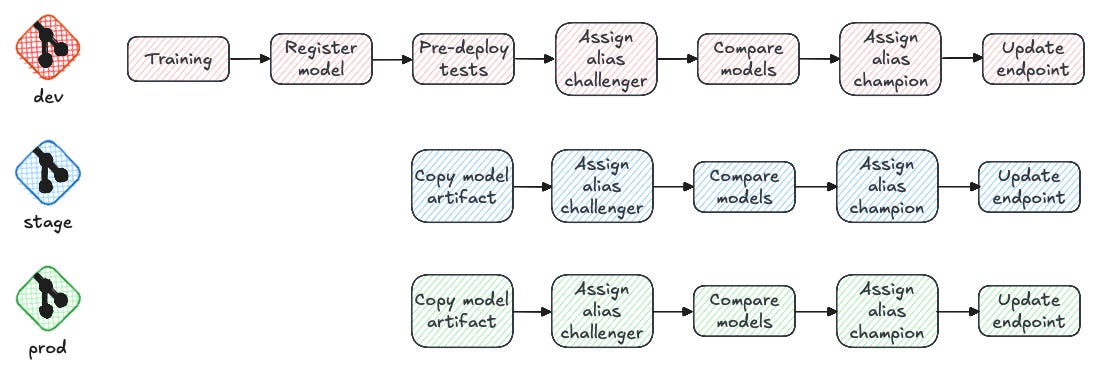
The approaches in MLflow and SageMaker are very similar, with the main difference being their model version management terminology. MLflow uses Champion and Challenger aliases to nominate best model for deployment, while SageMaker uses an approve/reject system. Also, it's worth mentioning that all models registered in MLflow are automatically synchronized to the SageMaker Model Registry.
Deployment difference
Regarding pipeline automation and deployment, there has been a change in capabilities. Previously, CodeCommit events sent to EventBridge enabled the creation of a fully event-driven MLOps pipeline. Currently, the event-driven automation is more limited — only the deployment phase of the pipeline can be triggered using SageMaker Model Registry events. The first part — training pipeline — should be triggered by CI/CD tool, for example GitHub Actions.
Infrastructure setup is slightly different for Databricks: you should use CI/CD tool for both training and deployment pipelines, as there is no direct events integration with EventBridge. You can setup web hooks to trigger GitHub actions to trigger deployment pipeline.

Thank you for reading, let’s chat 💬
💬 What do you think about deploy code approach and its advantages?
💬 Which approach do you use, deploy model or deploy code?
💬 Do you have any tips for MLOps setup with SageMaker or Databricks?
I love hearing from readers 🫶🏻 Please feel free to drop comments, questions, and opinions below👇🏻
