

🤓 While CPU and memory utilization serve as foundation metrics, truly resilient architectures require more sophisticated scaling strategies.
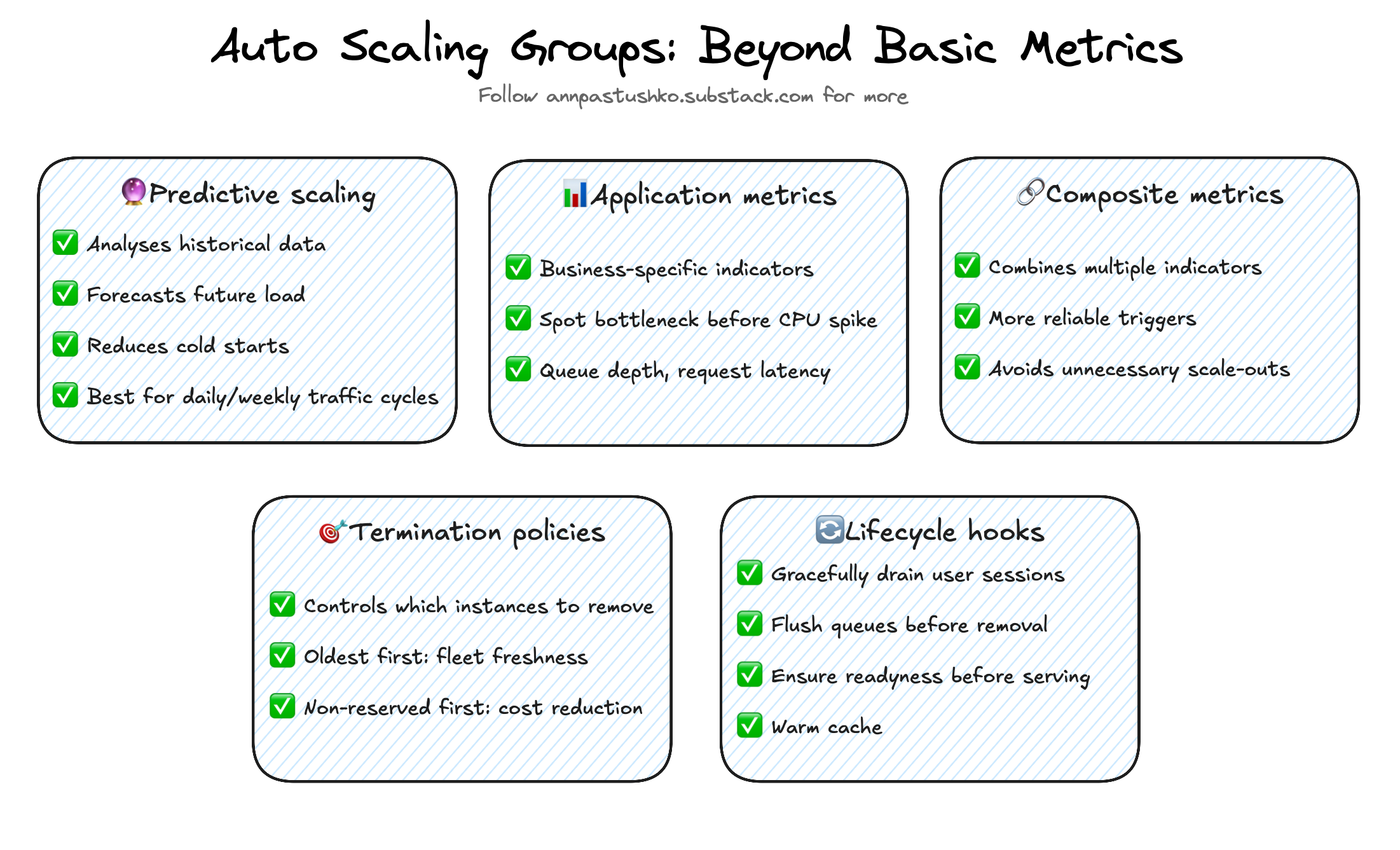
Predictive scaling
Reactive scaling waits for metrics to cross thresholds. By the time CPU usage is high, users may already see degraded performance. Predictive scaling flips that model. AWS Auto Scaling Predictive Scaling analyzes historical usage patterns and forecasts future load. When the system expects a surge, it provisions capacity in advance.
This works well for workloads with daily or weekly traffic cycles — such as e-commerce traffic peaking at specific hours, or reporting systems that see load at the start of each business day. It’s less effective for completely unpredictable traffic, but when patterns exist, predictive scaling can reduce cold starts and latency significantly.
Application-related metrics
CPU utilization doesn’t always represent user experience. A web service can show low CPU usage but still stall because of exhausted database connections or queue backlogs. That’s why it’s critical to monitor application-level metrics: queue depth, request latency, concurrent sessions, or DB connection saturation.
For example, in a payments API, spikes in transaction queue depth are often the first sign of overload. Scaling on queue length rather than CPU ensures capacity grows before users feel the delay. These business-specific metrics often surface bottlenecks long before infrastructure metrics react.
Composite metrics
Sometimes a single signal is too noisy. Combining multiple indicators creates more reliable triggers. CloudWatch math expressions allow you to define conditions such as: scale out only when both response time exceeds 200 ms and database connections approach their limit.
This avoids unnecessary scale-outs caused by transient spikes in one metric, while still protecting the system when multiple stress signals appear together. Composite conditions require more tuning, but they help keep scaling precise and cost-efficient.
Instance termination policies
Scaling in is just as important as scaling out. By default, Auto Scaling Groups can terminate any instance, but AWS offers termination policies to control the process. Choosing which instances to remove affects both cost and availability.
For example, terminating the oldest instances first can improve availability by cycling out machines that may be less reliable or missing recent patches, helping maintain fleet freshness. However, if you're using Reserved Instances or have specific cost optimization strategies, you might prefer terminating instances that aren't covered by reservations first to maximize your savings. Additionally, considering factors like instance launch time can help balance workload distribution and avoid disrupting long-running processes.
Lifecycle hooks
Scaling transitions are moments of risk. A new instance may join before it’s warmed up, or an old one may drop connections abruptly. Lifecycle hooks solve this by inserting custom steps during scale-out and scale-in events.
With pre-termination hooks, you can gracefully drain user sessions or flush queues before removing an instance. With post-launch hooks, you can warm caches or initialize applications before they enter service. This makes scaling invisible to end users and prevents performance degradation during transitions. Lifecycle hooks have timeout limits (default 1 hour, max 48 hours) which should be considered in planning.
Thank you for reading, let’s chat 💬
💬 Which scaling strategy have you found most effective in your workloads — and why?
💬 Do you use scaling beyond CPU and memory?
💬 Have scaling events ever caused downtime for your app?
I love hearing from readers 🫶🏻 Please feel free to drop comments, questions, and opinions below👇🏻
